Overview of the ETL workflow
This topic contains the following sections:
ETL workflow
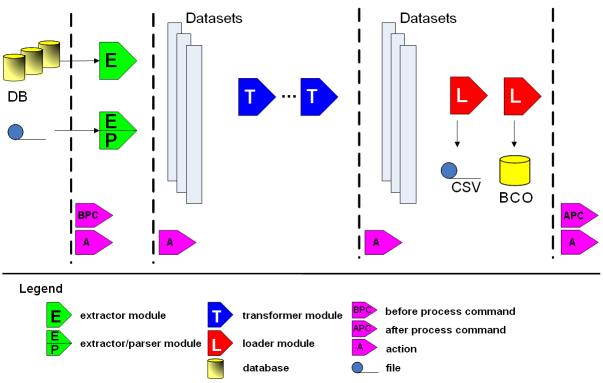
The ETL (Extract, Transform and Load) process is realized by different modules that run on top of a common engine framework (see ETL development API constructs for details). As shown in the diagram, the data import process is divided in three phases:
- Data extraction phase
- (Optional) A "before process command" can be executed in order to perform tasks which may be necessary to the import procedure (for example, locking the database schema, telling the monitoring application to flush its data to a CSV file, etc).
- The extractor module reads the data from an external database or file; these data are generally gathered by a third party monitoring application.
- If the source data resides on a file, the extractor feeds them to a parser module.
- Data are now converted to the internal representation format: the dataset.
- Transformation phase
- (Optional) One or more transformer modules read the dataset data and perform some in-memory transformations; this phase is optional and its application depends on the extracted data.
- Loading phase
- One or more loader modules store the dataset data into the BMC TrueSight Capacity Optimization Data Warehouse. By default, BMC TrueSight Capacity Optimization imports the data into its own warehouse and also writes it to a CVS file so that it can be used by other applications; you can also configure a new loader to export the data somewhere else, for example, to another database.
- (Optional) An "after process command" can be executed after the import process has been completed.
During the loading phase, the ETL engine stores data into the stage area. The warehousing engine completes the job by processing the data and aggregating it at the standard time aggregation levels.
Additional information
It is important to note that "before" and "after" commands are part of the import process but have nothing to do with the data itself: they are simply instrumental to the smooth execution of the process. These commands can be written in any language, for example, shell script, Java, C#, etc.
Tip
An action is an operation that can be performed at any step of the import process and that generally deals with data manipulation.
The modularity of the process allows you to change many of its settings and modules by only editing the configuration, without writing a single line of code.
The following diagram summarizes the standard ETL workflow:
Entity name resolution
Sometimes data sources adhere to a naming convention that is different from the one used by BMC TrueSight Capacity Optimization: This makes it necessary to translate names according to the naming policy of the data warehouse.
It is possible to configure ETL-specific lookup tables which set, for each entity, the translation from the name used by the ETL task (ds_sysnm or ds_wklnm metrics) to the identifier used into the data warehouse (sysnm or wklnm). This process decouples sources naming from DWH naming and is unique for each ETL.
The lookup tables are automatically populated by ETL tasks when they find new objects in the source data; a new entry will be created for each new object, with identical data warehouse and data source names. You can manually modify the DWH name to make it comply to the BMC TrueSight Capacity Optimization naming policies.
Additional information
BMC TrueSight Capacity Optimization has no built-in naming policy. You can set your own naming policy and then ensure that each new entity name complies to it.
It is important to spot potential naming conflicts when creating new ETL tasks.
If the measured entities are new, the ETL will automatically propose a name that you can manually modify. On the other hand, if the entities are already measured by another ETL, they are already associated to a name in the warehouse.
If you detect this situation before the first run of the ETL task, you can perform manual or shared lookup and solve the issue; this is the recommended solution. If you detect this situation only after running the ETL task, then the reconciliation process has to be performed.
Additional information
To avoid naming conflicts, remember to run a newly configured ETL task in simulation mode, and to check the imported data before actually importing it into the BMC TrueSight Capacity Optimization Data Warehouse. Lookup reconciliation is possible but discouraged; you should always try to fix every lookup issue before running the ETL task for the first time.
lastcounter parameter
When running ETL tasks, only new data must be loaded into the warehouse; thus, a way to mark imported data is needed.
Each ETL has an associated parameter called lastcounter which keeps track of the last imported samples. This counter is updated after every run and, at the start of the next one, the extractor module reads it to distinguish between old and new data.
As ETL extractors deal with both databases and files, a different lastcounter logic is required. It can be a timestamp, as it is usually for ETL tasks that collect data from databases, or a regular expression, to prevent the ETL task to parse files with a specific extension indicating that they have been already examined. In particular:
- Database extractors usually store the data's timestamp or ROWID as lastcounter; this procedure is very accurate.
- File extractors generally mark the parsed file with a done suffix and move it to an archive directory, or recognize unparsed files through a file name pattern. The last method involves a file name pattern containing the creation date: the ETL looks for files created the day before the execution, and imports them. A problem arises if you missed an ETL task run: you have to manually edit the lastcounter parameter to recover files that were not imported.
Comments
Log in or register to comment.